



 Les entreprises qui présentent leur algorithme comme une boîte noire opaque n’ont pas un grand avenir. Dommage pour les spécialistes du retargeting comme Criteo, NextPerformance, Rocket Fuel ou MyThings qui gagneraient à offrir plus de transparence et suivre l’exemple des DSP. Ainsi, du côté de Turn, DataXu, MediaMath et Appnexus les algorithmes qui optimisent les achats médias sont transparents. Alors, pourquoi encore parler de boîte noire magique? D’ailleurs c’est un sujet assez sensible et peu de professionnels souhaitent prendre la parole là dessus. Heureusement, Jay Friedmann le COO de Goodway Group s’est penché sur la question l’an dernier. Les résultats ne vont surprendre personne… quoique…
Les entreprises qui présentent leur algorithme comme une boîte noire opaque n’ont pas un grand avenir. Dommage pour les spécialistes du retargeting comme Criteo, NextPerformance, Rocket Fuel ou MyThings qui gagneraient à offrir plus de transparence et suivre l’exemple des DSP. Ainsi, du côté de Turn, DataXu, MediaMath et Appnexus les algorithmes qui optimisent les achats médias sont transparents. Alors, pourquoi encore parler de boîte noire magique? D’ailleurs c’est un sujet assez sensible et peu de professionnels souhaitent prendre la parole là dessus. Heureusement, Jay Friedmann le COO de Goodway Group s’est penché sur la question l’an dernier. Les résultats ne vont surprendre personne… quoique…
 Un exemple pour commencer : la taille de l’échantillon
Un exemple pour commencer : la taille de l’échantillon
Pour commencer, il est important de comprendre que n’importe quel algorithme doit avoir suffisamment de données sur une combinaison de variables données pour décider de sa valeur. Par exemple, vous ne prendriez pas un sondage d’une seule personne, car la taille de l’échantillon serait trop petit. Dans la cas d’une élection avec au moins deux candidats, vous avez besoin d’un échantillon de 1.067 personnes si vous savez qu’il y a 180 millions d’électeurs inscrits, que vous voulez une marge d’erreur de 3% et un niveau de confiance de 95 %. La marge d’erreur suit une courbe en cloche, comme ça. Ce qui suppose un niveau de confiance de 95 %.
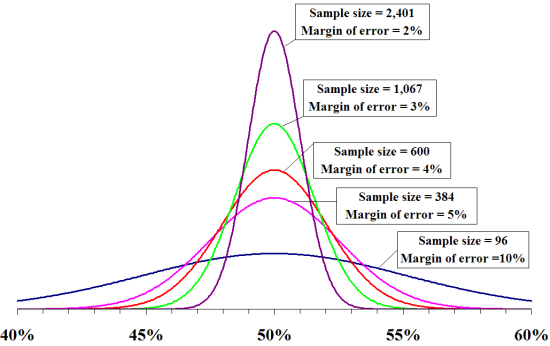
Même si les mathématiques n’étaient pas votre discipline favorite, il ne faut pas se laisser intimider. Pour lire le graphique, il faut comprendre que plus on monte plus la marge d’erreur inférieure est faible. Cela signifie simplement qu’il y a une bien meilleure chance que vos chiffres soient exacts.
Mais que faire s’il y avait 500 candidats et qu’aucun n’a été favorisé ? Le meilleur candidat obtient 0,8% , le plus bas de 0,02%. Avec un écart si faible, même la courbe la plus haute, celle à 2% d’erreur nous laisse dans l’incertitude pour savoir comment vraiment séparer les candidats. Par conséquent, il faudra augmenter la taille de l’échantillon.
 Voici comment cela se traduit par une campagne RTB en display, mobile ou vidéo
Voici comment cela se traduit par une campagne RTB en display, mobile ou vidéo
Au départ, on a 500 candidats, des sellers ou éditeurs, ce qui correspond à 3,6 milliards de combinaisons différentes. Dans une campagne RTB classique, on peut estimer 50 000 impressions sur un site avec un taux de conversion à 0,1 %. Cela équivaut à au total de 50 conversions. Si vous voulez aller plus loin, vous pouvez observer que 48 des 50 conversions ont eu lieu entre 7 heures et 10 heures du matin et qu’au sein de ces 48, 35 se sont produites lundi. Dans ces 35 , 27 étaient sur le système d’exploitation Windows 7 et ainsi de suite. On peut toujours aller plus loin en ajoutant de plus en plus de variables. Ainsi un site sera bon que certains jour ou même à une certaine heure de la journée. Sauf que dans cette équation on commence à avoir beaucoup beaucoup trop de variables.
– Jours de la semaine : 7
– Heures par jour :24
– Type de navigateurs : 6
– Dispositifs : 3
– Système d’exploitation : 4
– Sites : 10.000
– Format publicitaire : 3
 Cela fait au total un nombre de combinaisons uniques égal à 3628800000
Cela fait au total un nombre de combinaisons uniques égal à 3628800000
C’est vrai: Plus de 3 milliards de combinaisons uniques peuvent être prises en compte et c’est conservateur. Or on a à faire à plus de 50.000 sites et plus de 20 segments de données ce qui rendrait le nombre beaucoup plus grand.
Il y a deux façons de résoudre le problème : nous pouvons nous projeter «en avant» pour déterminer la taille de l’échantillon, comme dans l’exemple du sondage électoral ou bien « regarder en arrière » car il s’agit d’un scénario où nous avons déjà des données historiques. Si on estime qu’il y a 30 millions d’internautes en France et que l’on doit avoir une marge d’erreur de 0,001 %, la taille de l’échantillon doit maintenant être plus de 27 millions de personnes. C’est beaucoup pour un «échantillon». Alors regardons en arrière. Pour regarder en arrière , nous allons déterminer le nombre de « observations » ou d’impressions dont nous avons besoin par combinaison unique de valeurs pour dériver une décision statistiquement valide et fiable. Même si 10 observations ou impressions sont suffisantes, avez-vous les moyens de lancer une campagne avec plus de 36,2 milliards d’impressions, surtout pour un test ? Alors oui, l’algorithme parfait devrait théoriquement explorer toutes les combinaisons au sein des variables. Sauf qu’aucun algorithme n’est parfait. On pourrait se dire que l’algorithme va optimiser en fonction non pas du média, mais des internautes. Mais là encore c’est trop compliqué.
 Trouvez-moi la réponse de 100 millisecondes
Trouvez-moi la réponse de 100 millisecondes
S’éloignant des statistiques, nous allons aborder le mythe selon lequel aucun humain ne peut prendre des décisions en moins de 100 millisecondes. Mauvaise nouvelle, c’est la même chose pour les algorithmes.
La réalité est que la plupart des acteurs du RTB mettent en mémoire cache leur réponse afin qu’ils puissent répondre dans les 100 millisecondes et ne pas être dépassés. Pour ce faire, l’algorithme doit fonctionner indépendamment des enchères.
À ce stade, vous pourriez vous demander à quoi sert un algorithme sur les ad exchanges. Le but ici c’est des rafraîchir la température face à la magie de ces derniers. N’oubliez pas qu’un bon algorithme doit être transparent comme l’entreprise qui travaille avec. Alors maintenant, bon shopping.
Pierre Berendes

4 questions déja posées
Merci Pierre pour cet article très intéressant.
Vous l’aurez noté, je ne commente que très rarement vos articles. Mais en l’occurrence, je tiens simplement à vous apporter plusieurs éclairages
– nos algorithmes ne sont pas une boîte noire, ils sont auto-apprenant, c’est à dire que nos décisions d’achats (prix, critères) changent en permanence. Nous donnons à nos clients un nombre d’indicateurs très importants sur le fonctionnement de nos campagnes et des algorithmes sous-jaçents
– nos prix ne sont pas stockés en cache, ils sont calculés à 100% en temps réel, dans les 100millisecondes que vous signalez.
Ceçi pour une raison simple, nous calculons la probabilité de générer une conversion par utilisateur, et non pas par segment pré-construit, comme 99% des acteurs du marché le font. Nextperf fait bien du real-time advertising, et pas du semi-temps réel
Pour reprendre votre première phrase : « Les entreprises qui présentent leur algorithme comme une boite noire opaque n’ont pas un grand avenir. – See more at: http://ad-exchange.fr/les-mythes-et-realites-des-algoruthmes-sur-les-ad-exchanges-8529/#sthash.ylDezKOO.dpuf« .
Nous partageons le point de vue selon lequel les boîtes noires n’ont pas d’avenir, pour autant s’agissant de marketing à la performance (notre offre est au CPA / Cost of Sales), il convient de relativiser l’intérêt de la transparence totale sur la façon dont vous achetez votre média, en matière de performance marketing, seul le résultat compte.
S’il faut être transparent pour parfois justifier de résultats médiocres ou de ROI < aux objectifs du client, ce n'est pas non plus la solution ultime.
En conclusion : de la transparence : oui, de la performance : surtout.
Vincent Karachira
CEO Nextperf.
incroyable ces articles à charge …
forcément Appx et les autre technos en manage service sont transparentes sur leur algo puisqu’elles permettent justement à chaque utilisateur de les personnaliser.
les sociétés qui n’ont soient disant pas d’avenir que vous citez ont aujourd’hui fait leur preuve par leur techno justement. ces technos développées par des ingénieurs ne sont pas à la portée de chacun et sont aujourd’hui les plus performantes du marché. des centaines d’ingénieurs travaillent en continue pour les rendre plus performantes…
Ce blog soutenu et édité par les équipes de Makazi qui utilise Appx pourrait au moins être impartial et fair…
Nous sommes arrivés à une ère où malheureusement les petites courbes d’intervalle de confiance et autres petits algorithmes bien compréhensibles qui linéairisent à outrance les comportements et les décisions ne suffisent plus.
La complexité des algorithmes requise pour commencer à espérer traiter cet univers « sans fin » de données, dépassent le postulat obsolète mais humain de compréhension détaillée de leur fonctionnement.
L’avènement du BigData n’est pas un concept marketing mais une vraie problématique d’experts. Cette déferlente de données maintenant accessibles en provenance du web et la mutation des processus mentaux d’achats vers « l’irrationnel apparent » nous oblige à ré-envisager des algorithmes profondément abstraits avec le concours de machine surpuissante. L’extraction de connaissance à travers le chaos multi-dimensionnels d’informations qui frétillent chaque seconde, ne peut être processus conscient humain.
A ce jour, Imaginer que les « algorithmes noires » ultra-efficaces n’ont pas d’avenir, c’est ne pas comprendre que la complexité de leur écriture n’est plus accessibles à tous à cet instant, et c’est penser que les résultats intermédiaires produits sont toujours humainement interprétables.
Imaginez-vous que du jour au lendemain en plus de vos cinq sens (odorat, etc..) – des Millions de nouveaux capteurs externes sont à votre disposition pour percevoir le même monde….
Gilles Cymbalista